📢 Editor’s talk: 2023년 9월 14일부터 이틀간 열린 「LG SW 개발자 콘퍼런스(LG Software Developer Conference, 이하 LG SDC 2023)」. LG 계열사 내 개발자들의 경험과 열정을 공유하고 지식과 혁신적인 아이디어를 나눴던 시간, 구체적으로 살펴보겠습니다.

개인화 솔루션의 필요성
플랫폼 사업을 위해서 필요한 많은 요소 중에서도 데이터는 가장 중요한 성공요인입니다. 데이터는 플랫폼 비즈니스, 고도화된 기능, 개인화 서비스의 근간입니다. 따라서 얼마나 처리가 쉽고 활용도가 높은 고품질의 데이터가 확보 되었는지가 관건이죠.
흔히들 데이터를 석유에 많이 비교하는데요. 한번 쓰면 사라지는 휘발성이 강한 석유와 달리 데이터는 꾸준히 축적이 가능하여 이를 통해 고도화된 서비스와 양질의 제품들을 만들 수 있습니다. 하지만 이는 우리가 활용도 높은 데이터를 확보했을 때 비로소 실현 가능한 것으로 그 전에 많은 과정과 준비가 필요합니다.
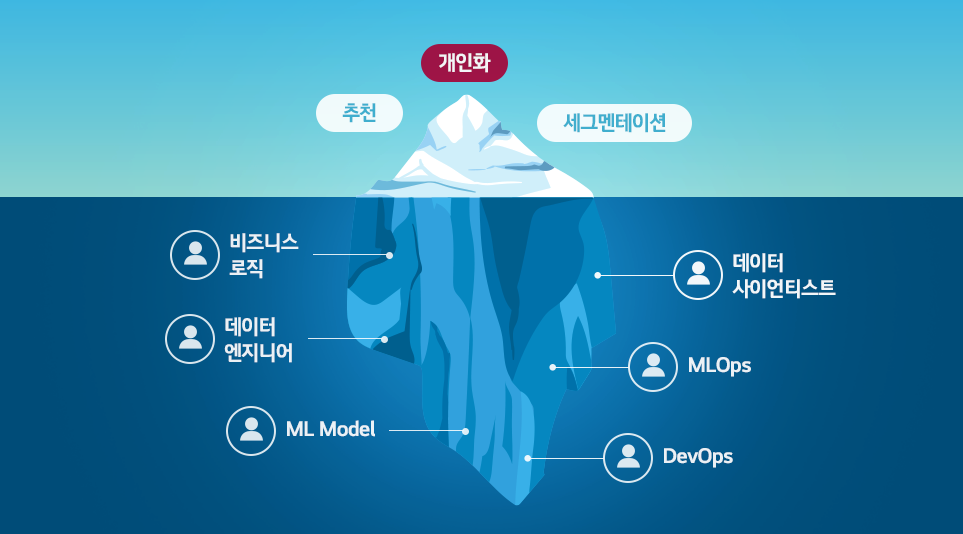
현재 고객 인게이지먼트 강화에 가장 효과적인 솔루션은 바로 ‘개인화 솔루션’입니다. 개인에 맞는 컨텐츠와 기능 등을 통해 더 많은 비즈니스를 창출하고, 또 이렇게 쌓인 고객 데이터를 고도화하며 선순환이 만들어집니다. 하지만 효과적인 개인화 솔루션을 도입하기 위해서는 빙산의 밑동처럼 비즈니스 로직은 물론, MLOps, Data 엔지니어, Data 과학자, DevOps 엔지니어 등 상상 이상으로 많은 리소스가 요구됩니다. 우리는 이들의 필요성을 느끼며 이런 측면들을 구축해나가기 시작했죠.
“데이터가 있는데, 데이터가 없다?”
데이터가 있는데 데이터가 없다? 어떻게 보면 역설적인 말이기도 합니다. 실제로 우리는 서비스를 만들고, 인터넷에 스마트 기기를 연결하고, 고객들이 앱을 사용하는 과정에서 하루에 수 백 기가에서 수 테라의 데이터를 수집합니다. LG전자 또한 앱 데이터, 서버 데이터, 제품 데이터 등 각종 외부 데이터를 보유하고 있습니다.

하지만 실제 개인화 기능을 위해 사용할 수 있는 데이터는 그리 많지 않습니다. 이는 우리가 보유하고 있는 데이터의 품질을 검증할 방법이 거의 없기 때문인데요. 이를 ‘좋은 데이터의 부재’라고도 표현합니다. 즉, 방대한 양의 데이터에서 고품질의 데이터를 뽑아낼 수 있는 플랫폼은 물론, 비즈니스 엔지니어, SW 엔지니어, DevOps 엔지니어, 데이터 사이언티스트 등 다양한 분야에서의 인력도 필요합니다.
LG전자 가전의 방대한 데이터를 활용하려면?
현재 저희는 LG전자에서 ThinQ라는 네이밍 안에서 여러 서비스를 개발하며 다양한 데이터를 다루고 있습니다. 오늘은 특별히 제품 데이터에 대해서 좀 더 집중적으로 얘기해보고자 합니다.
기본적으로 제조회사인 LG전자 특성상 제품에서 발현되는 데이터가 대부분을 차지하는데요. 이를 통해 굉장히 많은 고객들의 행동 데이터를 뽑아내야 합니다. 당장 H&A 제품만 하더라도 수천만 대 이상의 기기들이 서버에 등록되어 있을 만큼 굉장히 많은 제품군과 베리에이션이 있고, 또 비슷한 제품일지라도 디자인과 기능에 따라 데이터 사양이 조금씩 다릅니다. 실제로 2023년 8월 한국에서 하루 기준으로만 기가바이트급 이상의 가전 데이터가 쌓였는데요. 문제는 그 양이 계속 증가한다는 것입니다. 이렇게 엄청난 양의 제품 사용 경험 데이터를 일일이 처리하여 고객 맞춤형으로 가공하는 것은 굉장히 어려운 영역입니다.
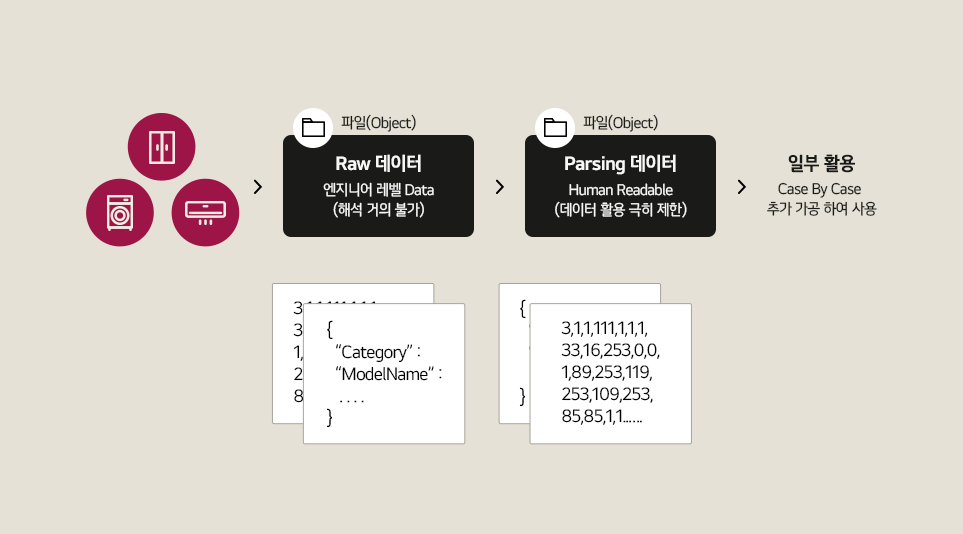
기존에는 제품에서 서버로 올린 Raw 데이터를 Parsing 데이터로 1차 가공하고, 이를 2차 처리하여 일부 서비스나 분석에 활용하는 방식이 대다수 였습니다. 하지만 Raw 데이터는 비용 효율을 극대화한 바이너리 데이터 형식으로 전문가가 아닌 이상 즉각적인 해석이 거의 불가합니다. Parsing 데이터 또한 몇십, 몇백배 증가하는 반정형 데이터로 활용성이 극히 어렵고 모델별로 상이하여 제품 지식 없이 활용하기 어렵습니다. 일부 전처리 과정을 통해 서비스에 활용되긴 했지만 특정 모델이나, 특정 데이터 필드에 국한되는 등 여러 문제도 있죠.
이처럼 제품에서 서버로 올라가는 데이터를 범용적으로 활용하는 것은 굉장히 어렵습니다. 따라서 범용 데이터로 활용하기 위해 “좋은 데이터 형태”로 만들어야 하고 좋은 데이터를 만들어내기 위해서는 굉장히 많은 기반 요소들이 필요합니다. 다행히도 LG전자는 디지털 전환(DX) 발표 이후 많은 조직들이 데이터 프로세스, 데이터 거버넌스, 데이터 문화적인 부분 등을 셋업하며 기반 요소들을 갖추었고, 이와 함께 데이터 플랫폼의 일환으로 표준화되고 정형화된 형태의 데이터를 만들어내는 데이터 큐레이션 시스템을 준비했습니다.
데이터 플랫폼의 역할은 무의미하게 흐트러져 있는 데이터를 쉽게 분석할 수 있게 정제한 후 이를 서비스에 적용하는 것입니다. 또한 누구나 쉽게 쓸 수 있는 정형화 된 데이터를 구축하는 일련의 과정을 거쳐야 하죠. 이를 데이터 큐레이션(Data Curation)이라고 합니다.
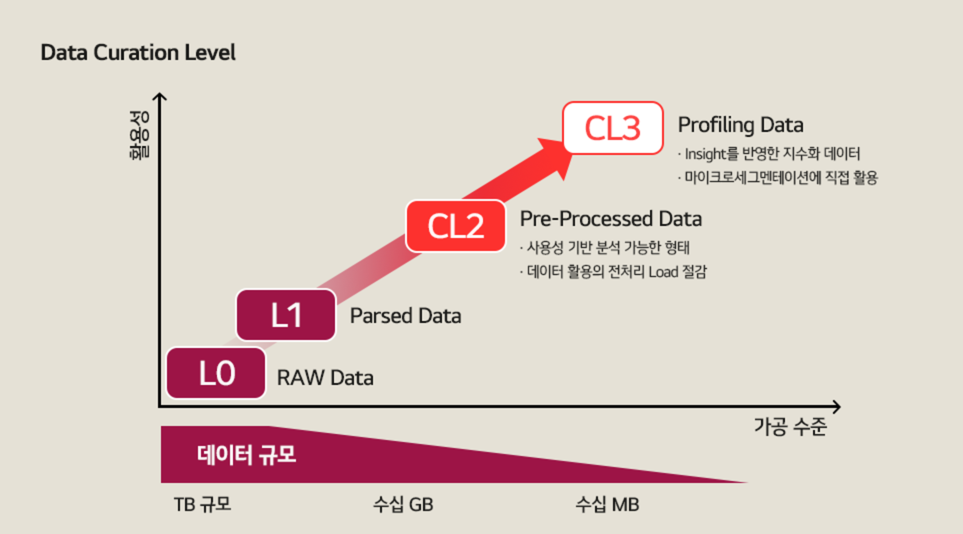
데이터 큐레이션은 의도와 목적성을 가진 표준화 데이터를 만드는 것입니다. 데이터 큐레이션을 통해 생성된 데이터의 경우 분명한 목적성도 가지고 있지만, 동시에 표준화/정형화된 데이터 형태이기 때문에, 개발자가 아닌 일반적인 수준의 인원(기획, UX 등)들도 빠르게 이해할 수 있는 수준의 데이터입니다. 기존에 Parsed 형태의 데이터에서는 인사이트를 얻어내기가 거의 불가능하거나 많은 공수가 드는 개별 가공 처리가 필요했지만, 데이터 큐레이션을 통해 생성된 데이터에서는 간단한 쿼리 기반의 집계, 통계를 통하여 인사이트 결과를 쉽게 찾아 낼 수 있습니다. 또한 큐레이션 데이터를 다시 고객 관점으로 프로파일링(Profiling)하여 추가적인 인사이트를 뽑아낼 수도 있는데요. 예를 들어 데이터를 통해 위생에 관심이 있는 고객 지수를 확인할 수 있는 것이죠.
현재 저희 팀은 CL2 (Curation Level2) 수준 이상의 데이터를 만들어내는 것을 목적으로 하고 있습니다. 이는 테라바이트 수준까지 쌓인 데이터를 99.9%까지 줄일 수 있어 활용성 뿐만 아니라 비용 측면에서도 굉장히 효율적입니다. 여기서 가공된 표준 데이터를 프로파일링하여 얻은 인사이트로 고객들에게 최적화 된 서비스를 제공하는 등 다양한 시도를 할 수 있는 것이죠.
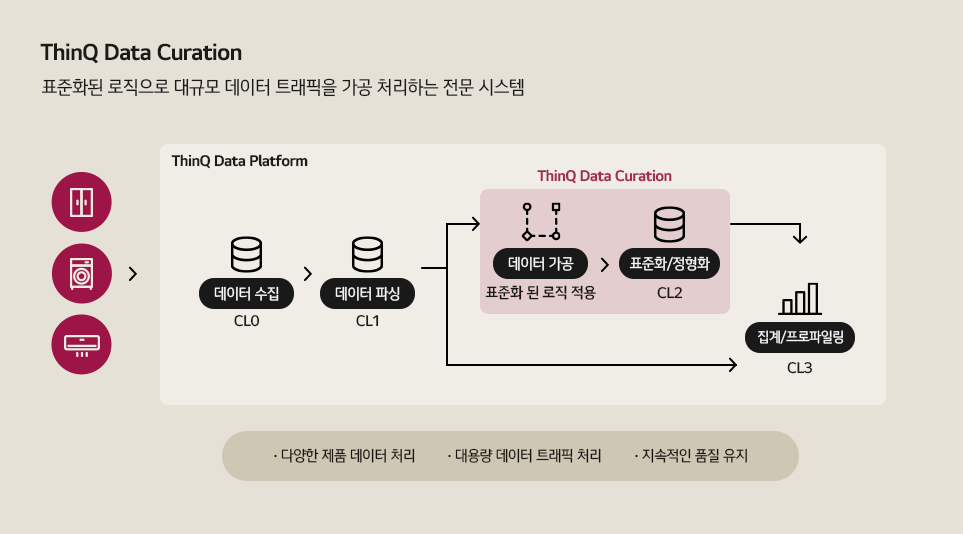
개인화를 위한 ‘데이터 큐레이션 시스템’
저희는 일반적인 룰 기반의 비즈니스 로직을 넘어, 개인 고객의 특성들이 반영된 된 개인화 로직을 구축하기 위해 머신러닝을 적극 활용하고 있고, 여기에 필요한 ‘좋은 데이터’를 만들기 위해 TDC(ThinQ Data Curation)라는 큐레이션 시스템을 구축했습니다. 기존에 구축해놓은 데이터 플랫폼 내에 이 큐레이션 시스템을 셋업하여, 표준화되고 정형화된 CL2 수준 이상의 데이터들을 뽑아내는 시스템을 만들었죠. 덕분에기획자와 개발자들이 빠르게 활용해 볼 수 있는 수준으로 정리할 수 있게 되었습니다.
하지만 데이터 가공 단계에서 다양한 제품군, 다양한 데이터 특성들을 처리하기 위해서는 여러 형태의 로직을 사용해야 합니다. 또한 데이터 파이프라인 처리과정에서 일어날 수 있는 이슈를 빠르게 확인하고 조치할 수 있어야 합니다. 이를 위해 저희는 쿠버네티스 등 플랫폼과 협업툴을 활용해 대규모 데이터를 효율적으로 병렬처리하고, 실시간 이슈 모니터링 및 빠른 조치를 취할 수 있는 환경을 만들고 있죠. 이를 통해 고객을 더 잘 이해할 수 있는 데이터를 확보해 나가고 있습니다.
이 과정은 앞으로도 지속되고, 새로운 제품이 출시되었을 땐 또 다른 로직이 나오면서 계속해서 발전해나갈 것입니다. 이렇게 만들어진 데이터는 기획은 물론, 영업 마케팅, 서비스 등 광범위한 분야에 쓰이며 더욱 효과적인 고객 개인화를 실현하게 될 것입니다.